

一、故障描述
用户VMware ESXi 7.0u3c在使用过程中,本地存储中的虚拟机突然无法访问,用户在检查本地存储卷显示为不可访问状态。
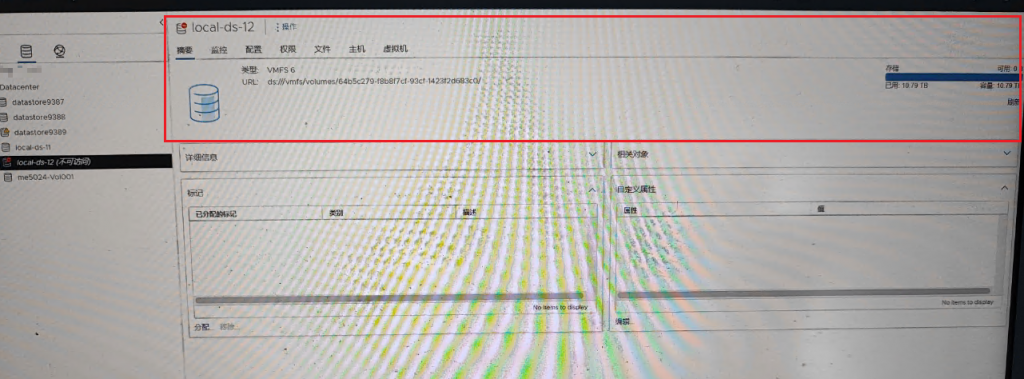
通过iDrac检查阵列卡状态,无法正确识别物理盘及RAID卷组。
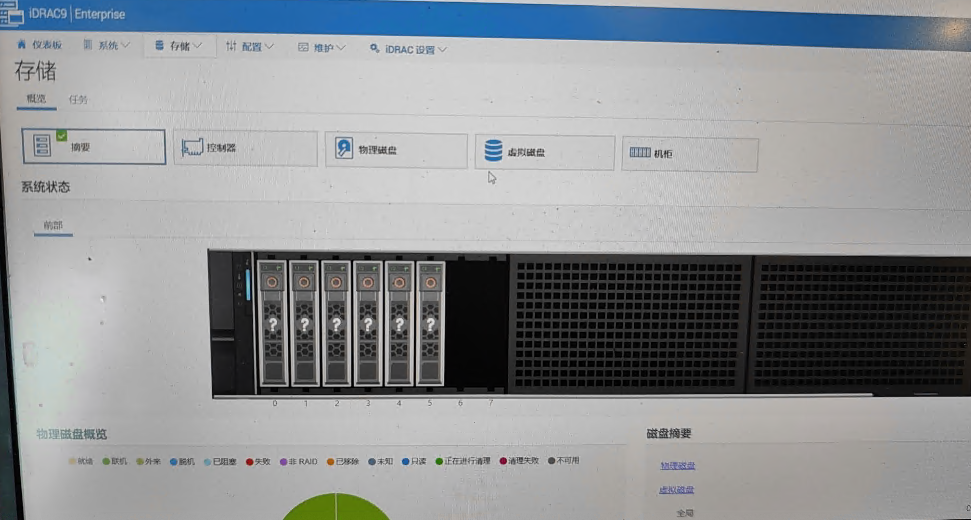
二、故障定位
以苏州天剑技术服务工程师的经验判断,可能是RAID卡的固件缺陷导致的问题,所以第一时间远程接入后即检查了RAID卡固件版本为52.21.0-4606,与DELL原厂核实后,当前RAID卡固件版本确实存在需要紧急升级的版本。
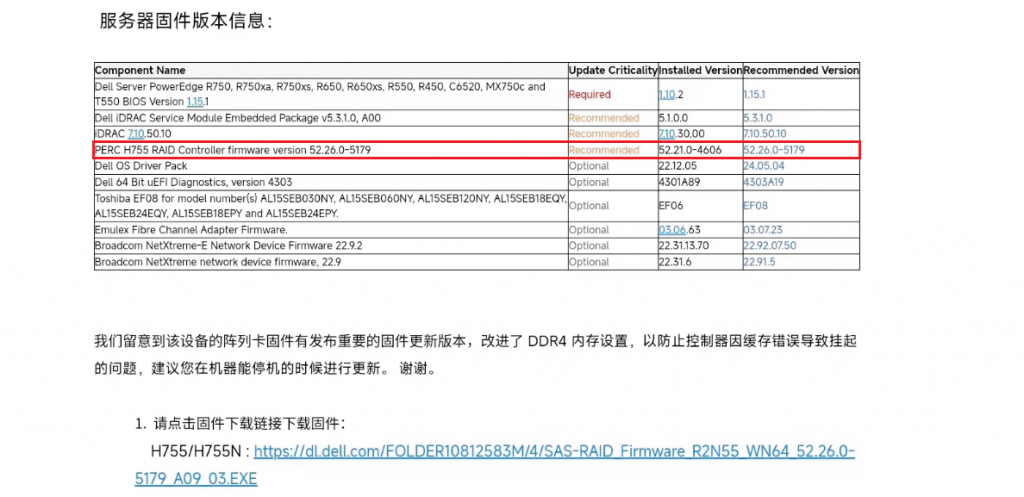
详细的描述可见:https://www.dell.com/support/kbdoc/en-us/000223831/perc11-perc-h750-h755-and-h755n-controllers-may-experience-single-or-multi-bit-ecc-messages,即当前RAID控制器固件版本,存在缓存错误导致挂起的情况,也符合当前的故障现象。
三、故障处置
与用户沟通停机时间后,将服务器进行冷重启,启动后Dirver Health Manager弹出提示:
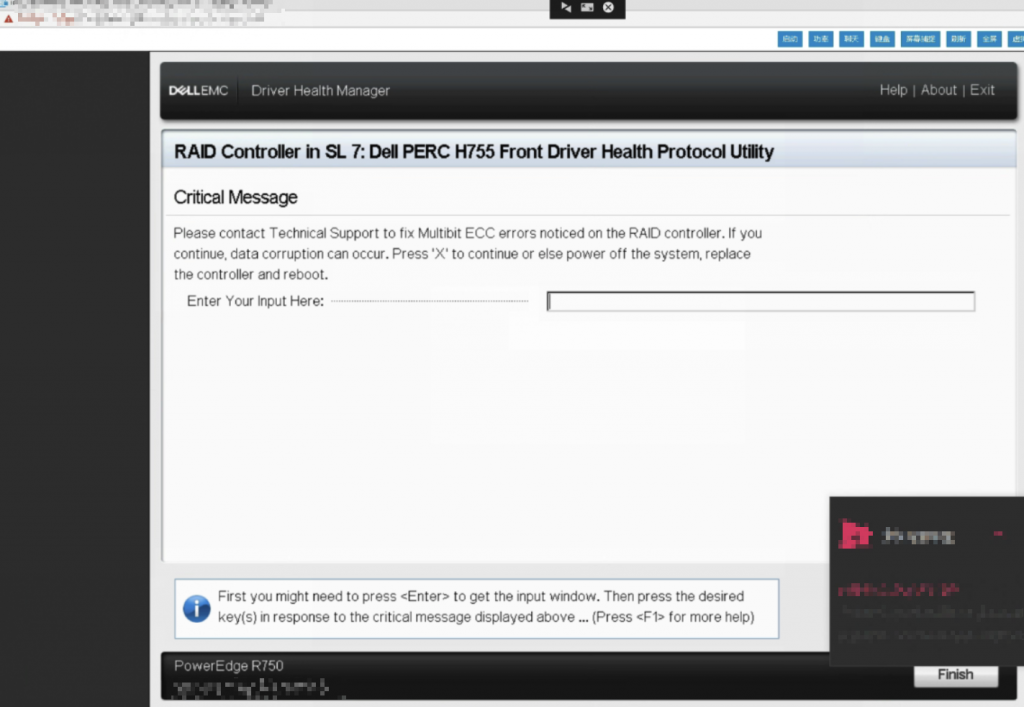
这是由于RAID卡产生了Multi-bit ECC Error,在启动过程中读到了LSI_RAID_Controller_info中的错误信息,这里仅需按X即可继续启动。
问题原因说明:
RAID卡具备ECC(Error Correcting Code)这种内存校验机制,采用奇偶性校验的方法,出现的ECC错误分为Single-bit ECC Error和Multi-bit ECC Error两种。
Single-bit ECC Error:只有单个bit出现了错误,能通过奇偶性校验恢复,因此RAID卡能容许出现一定次数的Single-bit ECC Error。iBMC会从RAID卡获取出现错误的次数和产生告警的门限,当次数≥门限时,iBMC会产生告警并记录维护日志。
Multi-bit ECC Error:有多个bit出现了错误,不能通过奇偶性校验恢复,因此RAID卡通常会出现挂死,进而导致系统挂死甚至系统重启。RAID卡挂死后,iBMC无法通过RAID卡检测到产生了Multi-bit ECC Error,因此iBMC无法产生告警。系统重启后,Multi-bit ECC Error可能恢复,此时iBMC可以从RAID卡获取到一次Multi-bit ECC Error事件,并记录在LSI_RAID_Controller_info里,这个是在multi-bit ECC Error发生且系统重启之后延迟记录的。
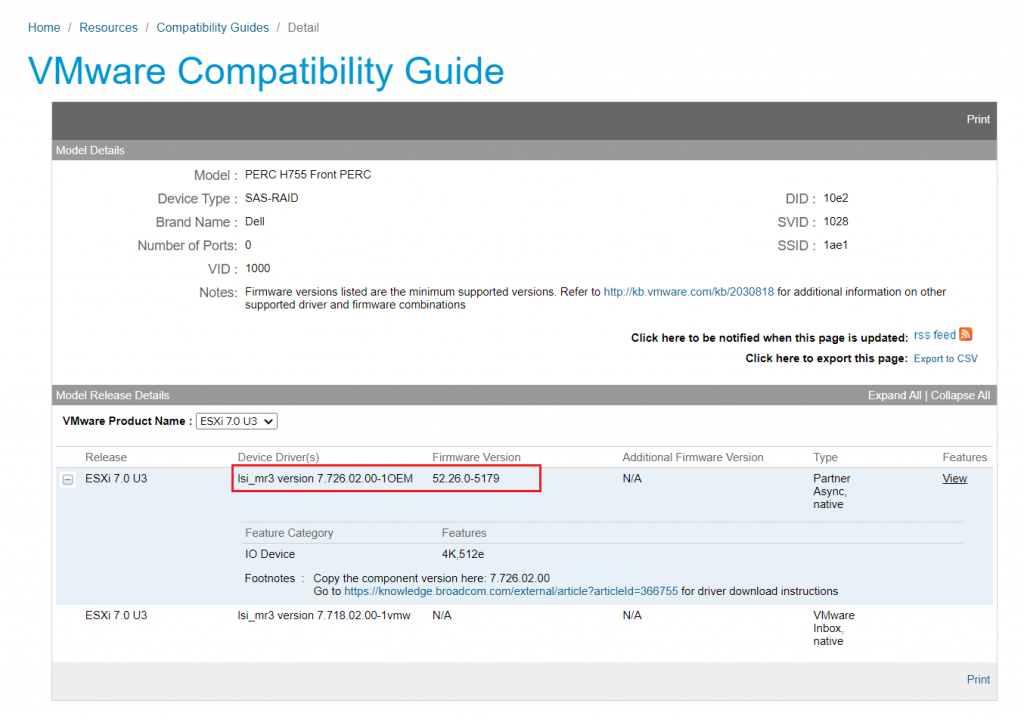
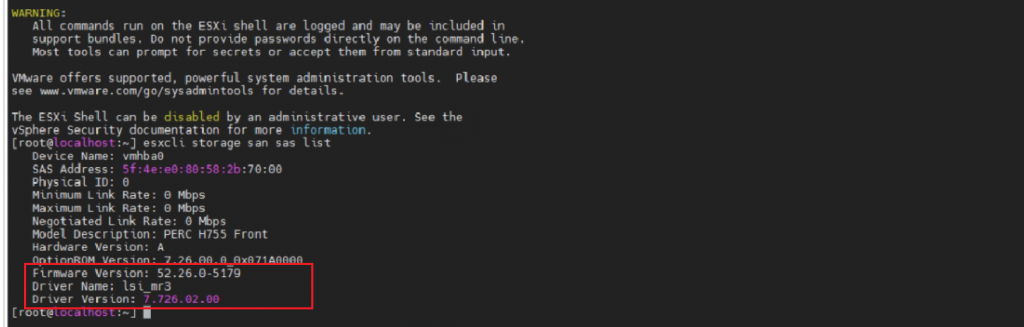
iDrac顺利识别到RAID卡后,按正常升级步骤升级合适的固件版本即可,同时检查VMware兼容性要求,苏州天剑服务工程师趁停机的机会一并升级了ESXi驱动,以满足兼容性要求。
四、总结
兼容性检查是保障稳定可靠的生产环境的最低基线,一定要及时定期检查如BIOS、RAID卡、HBA卡、网卡等关键硬件的兼容性是否满足兼容性列表要求!